





















With digitization and machine learning truly in their swansong days, the need to instantly understand, process, transform and deliver new data has never been greater. Streaming data pipelines emerged as the obvious choice for most businesses and they’ve been at the cornerstone of real-time data delivery ever since.
But some businesses and IT engineers aren’t familiar with data pipelines altogether and struggle with their implementation or run into various roadblocks along the way. Our article today aims to provide a comprehensive guide on streaming data pipelines and all their accompanying information.
By the end of this post, your business will be fully equipped with the knowledge and resources required to build a stable and reliable streaming data pipeline. And following our comprehensive feature list, you can make sure your development teams don’t miss out on anything.
What Are Streaming Data Pipelines?
The Digital Revolution is often attributed to the popularity and influx of AI and machine learning models, but here’s an alternative to this commonly-held belief: what if the Digital Revolution began with data transmission? Streaming data pipelines have long been in use and aren’t new to websites and apps alone.
A streaming data pipeline refers to the set of streaming platforms and processes used to automate and facilitate the movement of data between a source system like relational databases and the destination, such as a data warehouse.
The purpose of this pipeline is to continuously flow data to populate data lakes, data warehouses, or other repositories.


To the end user, this system works to provide near real-time analytics in the form of messaging apps that display new messages as they come, as news tickers online, or sports scores on the Google card. The technology works anywhere data is required constantly without the user needing to refresh their webpage or app.
Streaming data pipelines are also critical to the behind-the-scenes operations of many systems that help our society function. If your credit card has ever blocked a fraudulent charge, or an online retailer informed you that the item you were looking at just went out of stock, you’ve benefitted from a system that is reacted in real-time. That means a streaming data pipeline was involved.
Streaming data pipelines are different from most data pipelines because they handle data continuously — in near-real-time. But they still have the fundamental pieces of a data pipeline.
These are:
- Source
- Processing steps
- Destination
Whenever data has to move from one point to another, it requires a pipeline architecture to get to its destination (end-user).
For instance, customer data from a relational database is analyzed before being sent to a live chat with a particular customer. The chat bot instantly knows the customer’s contact information and history, so it can provide a custom experience.
It can be argued that rudimentary and less-automated versions existed during the broadcasting days of TV. Take a look at this Teletext from the 90s displaying football scores.


Contrast this to how live scores are displayed online on Google today.


Besides the higher fidelity graphics, sharper texts, and integration for matchday videos, one of the biggest changes between the two methods is how this data was transmitted.
The former relied on TV channels to manually update viewers on scores whereas the latter constantly updates based on data fed through streaming data pipelines. Similar concepts work for Twitter feeds, stock market update websites, and even a Twitch chat.
Businesses are looking to build apps with smaller code bases that have unique and specific purposes. Moving data between these applications require efficient data pipeline planning and development. One pipeline may feed multiple others and these can have other interconnected outputs, essentially creating a data map.
How do streaming data pipelines work?
Streaming data pipelines are built on technology systems called event brokers, otherwise known as event buses. They are event driven and move data in real time (or as close to real time as possible).
What does this mean?
The event broker detects changes of state in the source data — when a piece of data is added, updated, or deleted. It instantly fires off a message conveying this change of state. The message flows through the pipeline, arriving at the destination system in milliseconds (as long as no intervening process slows it down).
Thus, with a streaming data pipeline, even the smallest changes in data in the source system are reflected in the destination system more or less at the same time.
Though streaming is growing in popularity, most data pipelines today still use a different method called batch processing.
With batch processing, the source data is periodically scanned, or queried. All the changes that occurred since the last scan are collected are transported through the pipeline at the same time. This means there’s a delay between when data appears at the source, and when it gets through the pipeline to the destination.
What is A Big Data Pipeline?
Streaming data pipelines are particularly helpful for transporting big data.


Big data refers to the volume and complexity of data that has inundated our digital apparatuses in recent years. Ever since cloud technology became more accessible, users have come to expect large volumes, varieties, and velocities of data to be transmitted to their phones and digital gadgets.
Big data’s real-time applications can range from a variety of use cases such as:
- Predictive analytics
- System configuration
- Disaster management reports
- Real-time reporting and alerting
Alongside big data, the architecture to run it and support its increasing demand has also gone through a digital transformation.
Today, streaming data pipelines are created to facilitate any one of three traits of big data. These are:
- Velocity – The speed of big data transmission requires streaming data pipeline building.
- Volume – The volume of big data is huge and changes quickly. Streaming data pipelines are a more scalable and often cheaper way to accommodate growing demands.
- Variety – Intelligently designed streaming data pipelines can be re-purposed to handle the variety of structured, semi-structured, and unstructured data formats we commonly see.
In practice, multiple big data events can happen simultaneously which demands data pipelines to cope with the demand, speed, and the increasing variability of big data.
Data Pipeline vs ETL


Most developers are confused between data pipelines and ETL. We don’t blame them since the two concepts can seem similar at first glance.
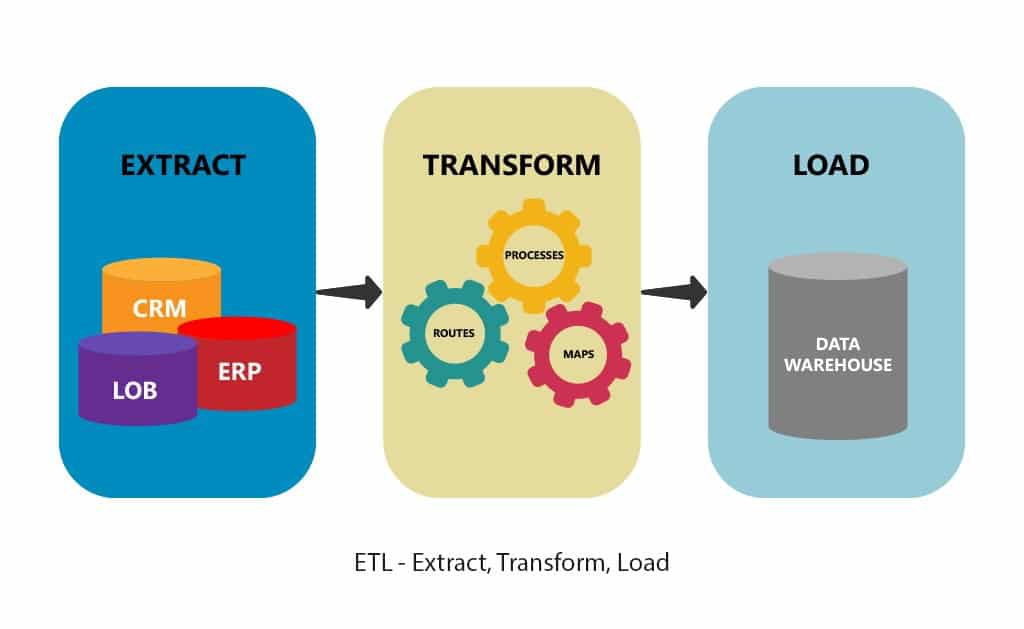
ETL is a type of data pipeline and has three major steps in how it works.
Step 1: Extract
Ingesting data from the source — usually multiple, disparate source systems.
Step 2: Transform
Transforming, or re-shaping the data in a temporary staging area. This step is important in ensuring that all data meets predefined formats for further use.
Step 3: Loading
Loading reformatted data to the final storage destination.
ETL is a common approach to moving data, but not all data pipelines are ETL. For instance, not every pipeline has a transformation stage. This minor shift can change a lot in how large swathes of data are converted and moved to storage.
ETL is useful when:
- Companies need to migrate data from legacy systems
- User data from different touchpoints need to be extracted
- Disparate datasets need to be joined for deeper analytics
However, ETL is archaic and a legacy data pipeline in itself, since it requires rebuilding every time requirements or data formats change. Additionally, traditional ETL processes data in batches. This adds a time delay, or latency, to the pipeline.
To counter these issues and manage workloads properly, ELT was developed.
In an ELT pipeline, the steps are reordered: data is loaded before it is transformed. This means that the pipeline can accept a variety of data formats with less delay. But ELT pipelines can quickly become too unstructured, leading data storage to descend into chaos.
Today, many data pipeline architectures exist that don’t fall neatly into either the ETL or ELT category — specifically where streaming data is concerned.
Estuary is one such example. It can be set up in minutes and doesn’t have the same niggling issues of a traditional ETL pipeline. It’s fundamentally a streaming platform, but with the familiar components common to ETL and ELT platforms. For convenience, we refer to what Estuary does as “real-time ELT,” but it’s actually much more complex.
Streaming Data Pipeline Components
To understand the mechanism of streaming data pipelines, it is important to understand what their components are. We’ll discuss six of the most prominent parts of a data pipeline:
I. Origin
The origin is the point of entry in the pipeline and can be any of the following data sources or storage systems:
- APIs
- Data lakes
- IoT devices
- Social media
- Public datasets
- Data warehouses
II. Event broker
The event broker (which we discussed above) is the technological backbone of a streaming data pipeline.
When it detects changes in data from the source, it instantly streams a message through the pipeline.
III. Pipeline tool
Event brokers don’t do much on their own. They are raw ingredients, and need structure to be effective. That’s why you need an interface or tool to provide the architecture of the pipeline itself.
This tool helps connect the event broker to the source and destination, and provides a way for users to interact with the pipeline.
For example, Apache Kafka is a popular event broker that many engineers use to build their own data pipelines. And Estuary is a pipeline tool built on an event broker called Gazette.
IV. Destination
The end-point of all data is called the destination. It can be multiple different things depending on the specific use case of the pipeline. For instance, it can be used to power data visualization and analytical tools or moved to storage.
V. Storage
Storage is the system or collection of systems where data is preserved as it moves through the different stages of the pipeline. The volume of data and queries, among other things, are important considerations for developers when selecting storage.
VI. Processing
Processing is the step that involves all the middle management that happens in between other steps. From ingesting data to data integration and storing, transforming, and delivering, all processes in the middle are referred to as processing. Most data processing is related to the data flow.
7 Features Every Modern Streaming Data Pipeline Should Have
By ensuring your data pipelines have these features, you’ll be less likely to run into problems, so your teams can make faster and better business decisions.


1. Real-Time Data Analytics And Processing
Near real-time loading, transforming, and analyzing modern data pipelines should be the ultimate goal of every business. By ensuring this, organizations may identify insights fast and take action on them.
New data should be prioritized and ingested without delay from databases, IoT devices, log files, messaging systems, and other sources. Log-based Change Data Capture (CDC) for databases is ideal for managing and streamlining real-time data.
Real-time data processing is better than batch processing (one of the key reasons why ETL fell out of favor), which can take hours or days to extract all information and transfer it efficiently.
In real-world scenarios, this can have massive consequences for your business. Imagine if TikTok batch-processed all its data. They would constantly be behind the latest social media trends and would lose out on profitability. Trends would rise and fade before the social media company would capitalize on them.
Similarly, vulnerabilities in a system would be reported late leading to unnecessary delays in reporting and patching. This case was prominent in the recent Nvidia security hack where the company was weeks behind in identifying a security vulnerability.
Real-time data pipelines give businesses more current data and in industries where downtime or processing time is non-negotiable, it can often mean playing with the fate of the entire company.
2. Fool-Proof Architecture
Data pipeline failure is an inevitability at this point. Something is bound to go wrong and almost always with data in transit. To get around this problem, pipelines should be reliable and available around the clock. This method alone can mitigate the impacts on mission-critical processes.
Most data pipelines are built in parallel so if one node goes down, it causes a bottleneck of data until the issue is resolved. However, modern data pipelines are designed with a distributed architecture which helps mitigate this issue.
In the event of a node failure, another from a nearby cluster takes over without manual intervention or debugging.
3. Implementing Cloud-Based Architecture
Data pipelines today use the cloud to enable businesses to scale computing and storage resources. As discussed earlier, modern data pipelines can handle resources from independent clusters simultaneously.
This architecture has allowed clusters to grow in number and size quickly and infinitely while maintaining access to the shared dataset. Data processing time has also consequently become easier to predict since new resources can support spikes in data volume instantly.
Cloud-native pipelines are elastic and scalable and can help businesses stay ahead of the curve. Without them, businesses find it harder to quickly respond to trends.
4. Process High Volumes of Data
Modern pipelines and businesses, as an extension, should be well equipped to process large volumes of semi-structured data (like JSON, HTML, and XML files) and unstructured data (including log files, sensor data, weather data, and more).
Since these two forms of data make up almost 80% of the data collected by companies, a strong focus must be kept on maintaining and processing them.
It is easier said than done, however, as most data has to be cleaned, standardized, enriched, and filtered. Once these processes are through, the data can go through aggregations.
5. Exactly-Once Processing


Data pipelines have two big issues that commonly present themselves: data loss and data duplication. Modern solutions have advanced checkpointing capabilities to ensure that no events are processed twice, duplicated, or missed. With checkpointing, businesses can keep track of all the events processed.
It can also act as a backup in case a failure occurs, allowing sources to rewind and replay data features.
6. Simplified Data Pipeline Development
Most modern pipelines are built with the principles of DataOps. This methodology combines various technologies to shorten development and delivery cycles. It automates data pipelines across the entire lifecycle. By following this methodology, pipelines are always on schedule when delivering data to the right stakeholder.
When businesses invest in streamlining pipeline deployment and development, it is easier to modify or scale pipelines to make room for new data sources. It also helps test data pipelines.
Modern pipelines are serverless and built in the cloud so test scenarios can be created rapidly and automated as well. These planned pipelines are then tested and, if necessary, are modified.
7. Self-Service Management
Modern data pipelines are interconnected via a variety of tools. Teams can utilize a variety of tools to quickly develop and maintain data pipelines. It takes considerable time for integrating other technologies in traditional data pipelines.
On the other hand, routine maintenance requires a lot of time and causes delays. Furthermore, traditional data pipelines frequently struggle to deal with different types of data. Modern pipelines help resolve all these issues. Systems become more automated and seamless, and data management gets simpler.
Overcoming Streaming Data Pipeline Complexities
Ensuring streaming data pipelines can have a lot of complications and risk improper implementation. It can risk the entire data processing workflow and to avoid this from happening, certain complexities need to be kept in mind.
Ensure that your business avoids the following pitfalls when implementing real-time data streaming:
A. Rigid Processing Pipelines
Stream processing stacks can often be tightly bound despite most pipeline concepts urging for loose coupling practices. Stream processing needs to be open and flexible with IT teams carefully considering how to approach its design and implementation.
Deployments of pipeline abstraction frameworks such as open-source Apache Beam can help mitigate this issue. It allows projects to use functionalities from a wider ecosystem of real-time data tech.
B. Ignoring Scalability
As referenced earlier, big data is one of the most substantial challenges to IT teams around the world. As data becomes more widespread, managing resourcing and storage can be time and resource-consuming.
This is an issue that larger teams can struggle with as well. It is recommended that IT teams document expected service levels and service levels expected of others. They can test in one-quarter of the production environment and load-test the pipeline to resolve any bottlenecks.
C. Using Legacy Methodologies
Legacy methodologies also hold back the proper implementation of data pipelines. This issue is mostly down to the tools that a growing team of data engineers uses to ingest and synchronize data. And with pipelines now moving to the cloud, it can present serious compatibility and functionality problems.
Try to unify all technology used by your teams and then proceed with the development and integration of data pipelines. This way, companies can ensure all aspects of deployment are the same across the board and that no issues present themselves.
D. Using a Single Platform
Today, many data tool vendors market their platforms as complete data stacks — they claim that they can handle storage, transport, and analysis equally well. It can be tempting, for example, to rely on your data warehouse’s native integrations instead of investing in a separate data pipeline.
Avoid buying into the hype and use each tool in its intended use case since this can simplify real-time data event streaming for businesses. The best data pipeline, data storage, and data analysis tools come from different companies. You’ll get your ideal setup if you mix and match.
Conclusion
Streaming data pipelines are essential for all data-driven businesses today and developing the most stable versions is vital for the proper flow and transmission of real-time data. Data engineering is often one of the more overlooked aspects of software and application development but is essential to optimize the product for end-users.
With our guidelines and best practices, you can ensure your data pipelines follow the highest quality standards and minimize unnecessary bottlenecks, node failures, and low-latency lags.
___________________________________________________
Interested in implementing or improving your business’s streaming data pipelines? Try Estuary for free.


{kind=link}
